Introduction
The record-based VSAM-SQL data bridge is one form of data transparency that enables the use of standard COBOL I/O statements (against indexed, relative or sequential datasets) to access data that has been extracted and stored in SQL tables on a record basis (i.e., each COBOL record is stored in its entirety as a single column value). "File" names in COBOL, ETP and EBP are denoted with file protocol VDB as in "VDB:CUSTOMERS.DAT" stored in a database as table "customers." An alternate form of the VSAM Transparency Mode stores each COBOL record element as a column in a table (file protocol "VSQL"). See Column-based VSAM-SQL Data Bridge for more information.
Data can be shared between Elastic Transaction Platform (ETP) processes, Elastic Batch Platform job steps, and non-ETP processes running concurrently on a single system or across multiple systems in a scale-out Heirloom Platform-as-a-Service (i.e., cloud) environment. VSQL and VDB protocols are the only forms of files supported by ETP across multiple, concurrent sessions unless the TCP/IP network-based remote files supported by the Elastic COBOL file and lock server.
Advantages of VDB over VSQL transparency mode include:
- Supports mixed record types (COBOL groups with REDEFINES)
- Does not require compiler support ($XFD directives) or an XML file
- Does not require side-files or properties to indicate file/table mapping
- Files (tables) and their indexes are created dynamically upon first reference
- Supports VSAM Keyed Sequence Dataset (KSDS), Relative Record Dataset (RRDS) and Entry Sequenced Dataset (ESDS) compatibility
- Loads files directly from SEQUENTIAL, LINE SEQUENTIAL, etc. via EBP IDCAMS or simple COBOL program that READs/WRITEs records at a time
- Performance is faster, especially if there are large numbers of elements in the COBOL record (the entire record is stored as a database BLOB column, making it more difficult for non-COBOL applications to access the data)
Advantages of VSQL over VDB transparency mode include:
- Ease of accessing "COBOL files" by non-COBOL programs using standard SQL (including JDBC APIs) without understanding the internal representation (e.g., packed decimal) of individual columns
- Leverage a database's ability to convert between different data types for a variety of uses
- Supports VSAM Keyed Sequence Dataset (KSDS) compatibility
- At the expense of performance, stores each COBOL element in a record as a separate database column (also allowing other non-COBOL applications to readily access the data)
Mapping a Dataset to a Table
VDB protocol uses the dataset (file) name specified on the COBOL SELECT statement, ASSIGN TO clause, or the file mapped to an environment variable or DDName in order to determine the corresponding database table name. Also, the dataset name can be used to specify other database artifacts such as user, schema, database and catalog as shown in the following table:
| Dataset Name | Database | Catalog | Schema (User) | Table | Notes |
| DB1.CAT1.USR1.TAB1.DAT | DB1 | CAT1 | USR1 | TAB1 | DBMS supports cross-reference databases and/or catalogs |
| DB1.CAT1.USR1.TAB1.DAT | current | none | public | TAB1 | DBMS does not support cross-reference database, catalogs and the schema is not defined or the DBMS uses "public" as a default schema |
| DB1.CAT1.USR1.TAB1.DAT | current | none | USR1 | TAB1 | "CREATE SCHEMA USR1" and appropriate permissions allow table creation |
| /usr/local/USR1.TAB1.DAT | current | none | public | TAB1 |
"USR1" was not created as a schema |
| C:\Users\Me\tab1.any | current | none | public | TAB1 |
"tab1" does not exist as a schema |
| tab1 | current | none | public | TAB1 |
Alternate indexes can be created for VDB files throughCOBOL programs that specify the Alternate Key clause on a new or existing VDB file. Or, they can be created through the IDCAMS utility with DEFINE AIX command. Since indexes are stored with the tables that contain the data, the "base" file name or table name must be the same. For example, an IDCAMS DEFINE CLUSTER may reference NAME(SYS1.CUST.DAT) and later DEFINE AIX should reference NAME(SYS1.CUST.IDX) or NAME(SYS1.CUST.XADDR) so that IDCAMS will create the index within the CUST table.
iDatabase tables used in VDB protocol are created in a certain way with fixed names and types of database columns and other attributes based on the attributes in the IDCAMS statement or on the COBOL File Control attributes. In general, because data is stored as an arbitrary length (variable or fixed) record sizes VDB uses binary large object (BLOB) data types which vary from database to database. For example, in PostgreSQL VDB uses the "bytea" (array of arbitrary bytes) column datatype to hold the data record and index columns.
The index columns store a redundant copy of that section of the data record that is kept in sync with the corresponding offset and length position of the data column. Adding an alternate index later (for example, with IDCAMS DEFINE INDEX command or by running a different COBOL program that specifies the Alternate Key clause in the File-Control section will cause the table to be altered with an additional column and then populated with the requisite values of the field.
Where BLOBs or their equivalents are not available, VARBINARY (with a max length specification greater than the computed COBOL group associated with the file) or LONG VARBINARY.
The table below shows COBOL File specifications and the DDL VDB uses to create the table in PostgreSQL. IBM DB2, MySQL, Oracle RDBMS, and Microsoft SQL Server may have slightly different column creation attributes. All of these SQL statements are issued by VDB when necessary, including creating tables and indexes.
| Organization / Type | File Attributes | SQL DDL Statements |
|
Indexed / KSDS |
Data Division. |
create table tab1( create index x_idx9_9 on |
|
Relative / RRDS |
Environment Division. |
create table tab2( |
| Sequential / ESDS | Environment Division. |
create table tab3( data bytea, seq serial primary key not null) |
The protocol specification for VDB can be given on the ASSIGN clause of the file descriptor within the COBOL program, and then takes affect for command-line execution of the program, from within an EBP batch job step, or from within an ETP transaction. When specified within the EBP environment it may be included in the Job Control Language (JCL), on the file specification for the IDCAMS standard utility. EBP supports the PROTOCOL keyword when creating (but not referencing) datasets. When VDB datasets are created in IDCAMS or JCL a Data Control Block (.dcb) file is created to retain these catalog-like parameters. Thus, the VDB dataset can be created in one step or job and referenced without attributes in a later step. Here are some examples of dataset, file, path mappings:
//MYDD DD DISP=SHR,PROTOCOL=VDB,DSN=DB1.CAT1.USR1.TAB1.DATSELECT CUST-FILE ASSIGN TO "VDB:DB1.CAT1.USR1.TAB1.DAT".SELECT CUST-FILE ASSIGN TO MYDD.
java -DMYDD=VDB:DB1.CAT1.USR1.TAB1.DAT MyPgm//AMSSTEP EXEC PGM=IDCAMS
//SYSIN DD *
DEFINE CLUSTER -
(NAME(DB1.CAT1.USR1.TAB1.DAT) -
PROTOCOL(VDB) -
INDEXED -
KEYS(10 0) -
UNIQUE -
RECORDSIZE(14 14) -
FREESPACE(10 10) )
DEFINE AIX -
(NAME(DB1.CAT1.USR1.TAB1.IDX) -
PROTOCOL(VDB) -
RELATE(DB1.CAT1.USR1.TAB1.DAT) -
NONUNIQUEKEY -
KEYS(4 10) )
REPRO -
INDATASET(SYS1.PS.DAT) -
OUTDATASET(DB1.CAT1.USR1.TAB1.DAT)
/*
Database Connections
Because the COBOL File I/O and JCL specifications don't allow for database-like connection information to be specified that can be used by VDB, a different mechanism relying on data source names and/or connection attributes are made to locate tables in one or more databases. The connection information may be supplied by the JEE server (when running under ETP), with specially-named side files containing the datasource or connection attributes when running under EBP or as System properties when COBOL programs are run from the command line. This mechanism is the same as to that which is used for the VSQL protocol. For a dataset with the base name (i.e., table name) of xxxx the data source name xxxx may be supplied by the JEE server to provide the database connection information necessary to find or create that table. If no DSN is available, individual connection attributes are retrieved from side files or System properties. The deploy_settings file, if in the packaged .war or .ear file or present in the current working directory, is a Java property file containing connection information.
- sql.xxxx.url=jdbc:postgresql://localhost/dbname
- sql.xxxx.user=postgres
- sql.xxxx.password=abc000
- sql.xxxx.driver=org.postgresql.Driver
- sql.xxx.autocommit=false
Note: see later discussion on Transactional VSAM support regarding autocommit.
When COBOL programs are invoked from the command-line the parameters should be supplied as system property definitions
java -Dsql.xxxx.url=jdbc:postgresql://localhost/dbname -Dsql.xxxx.user=postgres -Dsql.xxxx.password=abc000 -Dsql.xxxx.driver=org.postgresql.Driver myCobProg
Note that JDBC4 drivers may not need the driver configuration parameter if the JDBC DriverManager can locate the driver on the classpath.
When invoked by various utility programs under the auspices of EBP side files name IDCAMS.properties, IEFJK.properties, etc. are searched in the EBP datalib.1..9 configurations or an DD card with name PROPS indicates the line sequential dataset providing the connection information. EBP will retrieve the appropriate connection information for a job step and supply it to the COBOL program in the form of global properties specified on the command line. For example,
- xxxx.url=jdbc:postgresql://localhost/dbname
- xxxx.user=postgres
- xxxx.password=abc000
- xxxx.driver=org.postgresql.Driver
It is possible to provide multiple connections as System properties or in the side files. In this case the groups are ordered alphabetically and each connection is tried in sequence for each file open looking for the pre-defined table name. This allows the specification of multiple databases, possibly each with their own defined user schemas, to be used to segment the VSAM files. When tables are created the first with the appropriate CREATE TABLE permissions is used. If the following definition and operations are performed
Select CUSTOMERS ASSIGN TO "VDB:CUSTOMERS.DAT"
...
Select SUPPLIERS ASSIGN TO "VDB:SUPPLIERS.DAT"
...
OPEN CUSTOMERS INPUT.
OPEN SUPPLIERS INPUT.
the tables CUSTOMERS and SUPPLIERS may be housed in different databases and/or schemas and VDB will locate them during OPEN:
- cust.url=jdbc:postgresql://localhost/cust
- cust.user=postgres
- cust.password=abc000
- cust.driver=org.postgresql.Driver
- supl.url=jdbc:postgresql://remotehost/supl
- supl.user=postgres
- supl.password=abc000
- supl.driver=org.postgresql.Driver
ETP Integration
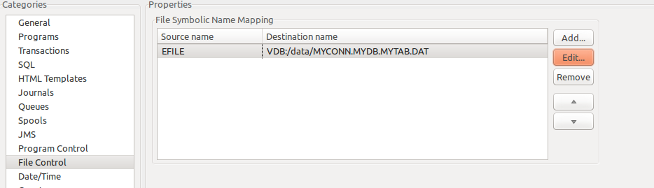
ETP (CICS) deployments using VDB must configure both File Control and SQL categories in the Elastic Transaction Platform Deployment Settings Editor. Because CICS I/O doesn't use COBOL file definitions the file must be defined beforehand, such as through EBP IDCAMS which will create a DCB entry used by ETP to establish the layout upon connection.
For example, below are the configurations required for an ETP transaction containing a code sequence such as
EXEC CICS
WRITE DATASET('EFILE')
FROM(CUST-REC) LENGTH(CUST-LNG)
RESP(CICS-RESP)
END-EXEC.
ETP Deployment Settings -- File Control
In the ETP Deployment Settings editor with the Eclipse Elastic COBOL IDE.
ETP Deployment Settings -- SQL
In the ETP Deployment Settings editor with the Eclipse Elastic COBOL IDE.
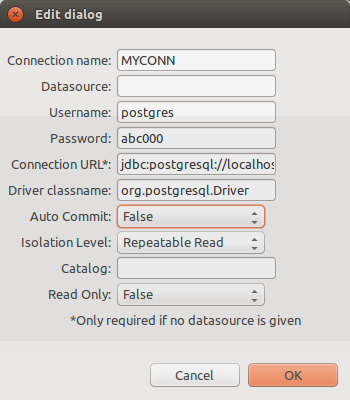
For traditional VSAM KSDS sharing operations (e.g., VSAM SHAREOPTIONS 3,3 or RLS, record-level sharing), set Auto Commit "True." For "transactional VSAM" operation which will include CICS I/O updates within the ETP transaction (controlled through SYNCPOINT processing), set Auto Commit "False" in the connection properties. When not auto-committing, VSAM Transparency Mode will commit changes to the database every 1000 records, by default. Use the runtime option -DDB-BUFFER-SIZE=n to change the default. This value also defines how many records are read-ahead on SEQUENTIAL file operations such as START and READ NEXT. This can improve read performance.
Indexed Dataset Definition -- MYCONN.MYDB.MYTAB.DAT
Input to EBP IDCAMS utility.
//MAKEKSDS JOB (HCIACCT),'DEFINE CLUSTER',CLASS=A,MSGCLASS=A,
// MSGLEVEL=(2,2),NOTIFY=USERID
//STEPID01 EXEC PGM=IDCAMS
//PROPS DD *
sql.myconn.url=jdbc:postgresql://localhost/tickets
sql.myconn.user=postgres
sql.myconn.password=abc000
sql.myconn.driver=org.postgresql.Driver
sql.myconn.autocommit=false
//SYSIN DD *
DEFINE CLUSTER(NAME('MYCONN.MYDB.MYTAB.DAT') -
PROTOCOL(VDB) -
INDEXED -
KEYS(10 0) -
RECORDSIZE(10 80)) -
UNIQUE
/*
//SYSPRINT DD SYSOUT=*
DCB Settings -- /data/.dcb
Created by IDCAMS DEFINE CLUSTER.
#Heirloom Computing, Inc. - Dataset Control Block
#Fri Jul 22 22:54:03 PDT 2016
MYCONN.MYDB.MYTAB.DAT-recmin=10
MYCONN.MYDB.MYTAB.DAT-keylen=10
MYCONN.MYDB.MYTAB.DAT-recfm=V
MYCONN.MYDB.MYTAB.DAT-recavg=10
MYCONN.MYDB.MYTAB.DAT-charset=ISO-8859-1
MYCONN.MYDB.MYTAB.DAT-dsorg=VS
MYCONN.MYDB.MYTAB.DAT-orient=INDEXED
MYCONN.MYDB.MYTAB.DAT-proto=VDB\:
MYCONN.MYDB.MYTAB.DAT-keyoff=0
MYCONN.MYDB.MYTAB.DAT-lrecl=80
MYCONN.MYDB.MYTAB.DAT-reuse=false
Table definition -- mytab
Created by IDCAMS DEFINE CLUSTER.
Table "public.mytab"
Column | Type | Modifiers | Storage | Stats target | Description
---------+-------+-----------+----------+--------------+-------------
data | bytea | | extended | |
idx0_10 | bytea | not null | extended | |
Indexes:
"mytab_pkey" PRIMARY KEY, btree (idx0_10)
Prior to packaging the .war or .ear with the ETP Deployment Wizard set the Java Build Path properties to include an additional library ("Add Jar...") referencing the appropriate JDBC driver. This will include the driver in the lib directory of the .war or .ear file and make it available for connection during your transaction.
File Operations
Operating on a VDB object is the same as operating on normal ISAM files, all of the associated verbs are allowed. They translate to the expected SQL statements. Some operations are different depending on the organization (Indexed, Relative, Sequential) as shown in the next table:
| Organization / Type Access |
COBOL Operation | CICS Operation | SQL Statement / JDBC API | Notes |
| All | OPEN OUTPUT | none |
create table ... |
dynamically create the table and indexes if necessary; open output implies emptying existing datasets |
| OPEN INPUT | none |
none |
check for correct columns, create new alternate index upon first reference |
|
| SYNCPOINT | commit() | under JEE transaction control | ||
| ROLLBACK | rollback() | under JEE transaction control | ||
| Indexed / KSDS | WRITE record | WRITE record | insert into tab(data, idx0_9, idx9_9) values(?,?,?) setBytes(1, report_rec.getBytes()) setBytes(2, rec_key1.getBytes()) setBytes(3, rec_key2.getBytes()) |
populate the database table via insert for BLOB columns |
| Access Is Random | START file KEY key1 | STARTBR file KEY key1 | select data from tab where idx0_9 = ? Statement.setFetchSize(1) |
retrieve result set of maximum of 1 record |
| Access Is Random | READ file KEY key1 | READ file KEY key1 |
select data from tab where idx0_9 = ? |
retrieve result set of maximum of 1 record |
| Access Is Dynamic | READ file KEY key2 | READ file KEY key2 |
select data from tab where idx0_9 = ? |
prepare for retrieving for multiple records |
| Access Is Dynamic, Sequential | READ file NEXT | READ NEXT file |
ResultSet.next() |
|
| REWRITE record KEY key1 | REWRITE record KEY key1 |
update tab set data = ? where idx0_9 = ? |
use explicit update statement on rewrite | |
| DELETE record KEY key1 | DELETE record KEY key1 |
delete from tab where idx0_9 = ? |
delete zero or more records matching the key | |
| Relative / RRDS | WRITE record | WRITE record |
insert into tab(data, rel) values(?,?) |
relative record key converted to integer and used as the primary key |
| READ file KEY key1 | READ file KEY key1 |
select data from tab where rel = ? |
always assume 1 record at a time | |
| Access Is Dynamic | READ file NEXT | READ NEXT file |
select data from tab where rel = ? |
close the prior result set and re-execute the query with a larger fetch size, skipping the first record. afterwards, simply use the ResultSet next() method for records 2 through n |
| REWRITE record KEY key1 | REWRITE record KEY key1 |
update tab set data = ? where rel = ? |
||
| DELETE record KEY key1 | DELETE record KEY key1 |
delete from tab where idx0_9 = ? |
delete one record (note that READ NEXT skips over holes) | |
| Sequential / ESDS | WRITE record | WRITE record |
insert into tab(data) values(?) |
database supplies the identity column value through auto-incrementing sequences kept per-table |
| READ record | READ record |
select data from tab order by seq |
READ, READ NEXT are the same, always start with the same query ordered by the auto-incremented sequence number and fetch in groups of 1000 records. | |
| REWRITE record | REWRITE record |
updBytes(1, report_rec.getBytes()) |
use cursor-like operations on ResultSet to update the most recent record read | |
| DELETE record | DELETE record |
none |
not defined in COBOL or CICS specifications |
Transaction Control
As with all databases, VDB protocol follows transaction protocol. When operating under ETP control is through the normal CICS operations. This effectively means "transactional VSAM" mode on the mainframe is always in effect for VDB. The database will control tuple-level locking among multiple sessions accessing the same record. JDBC CONCUR_UPDATABLE cursors are employed by VDB when files are writable and SCROLL_FORWARD_ONLY when operating in read-only mode.
When operating outside of ETP, such as EBP or command-line execution transaction control is determined by the standard file buffering runtime parameter Elastic COBOL uses for other protocol types, DB-BUFFER-SIZE. When set to 0 (the default) database connections will be made with autocommit on meaning each WRITE or REWRITE commits the data to the table immediately (also implying short lock duration). But, DB-BUFFER-SIZE non-zero indicates to VDB to commit after that number of operations whereas other protocols interpret it as a true buffer size in terms of bytes. So, if the -DDB-BUFFER-SIZE=1000 System property is set at the outset record inserts will be performed in batches of 1000. In addition it is possible to control the fetch size so that the resultset returned from a database table can be optimized, this is controlled using the DB-ROWS-TO-FETCH system property. The default for DB-ROWS-TO-FETCH is 1000. It is important to note that if jdbc autocommit is ON (the default setting for JDBC) then DB-BUFFER-SIZE will be ignored and so it is recommended for best control to set xxxx.autocommit=false in the relevant property file.
The following settings would simulate non-transaction file i-o, with every write being committed immediately to the database but still having read buffering enabled:
xxxx.autocommit=false //in the properties file
and -DDB-ROWS-TO-FETCH=100 -DDB-BUFFER-SIZE=1 on the command line of the program.
Transactions are also performed when files are CLOSEd and if intermingled READs (not READ NEXT) are performed through differing alternative indexes when combined with INSERTs or REWRITEs. ESDS REWRITE operations are performed through the result set retrieved as part of the READ or READ NEXT operation so the combined total number of operations (READ + REWRITE) are considered before commits are performed at DB-BUFFER-SIZE intervals.
Note that DB-BUFFER-SIZE and DB-ROWS-TO-FETCH can also be specified in the IDCAMS.properties file when running IDCAMS utility subsequently affecting repro performance.
Performance of VDB vs. File Systems
VDB (and its counterpart VSQL) are used primarily to gain scalability and availability of COBOL files over files. Whereas in z/OS VSAM files (with "share options 3,3") allow multiple programs and job steps to open, read and write records at the same time with a modicum of locking, the Java file system (on which Elastic COBOL, MF IDX3 and MF IDX8 file formats are based) does not allow this level of concurrency. Elastic COBOL offers the File and Record Lock Servers to get around this concurrency restriction but distributed use of such techniques has always been problematic. VDB, on the other hand, implements these functions with a formal relational database. Concurrency and tuple-level locking is controlled by the DBMS. Further, with the advent of cluster-able, in-memory resident and cloud-scalable databases a VDB system can support arbitrary ETP and EBP regions configured in a CICSPLEX or JESPLEX.
To verify relative performance the attached test TEST88.JCL EBP batch job was run against various VDB configurations with a variety of databases and compared against traditional (single-user) file formats. The results are in the table below. The test program generates random data for both a primary and alternate key. The job uses IDCAMS to load that data and then dump it in primary-key order or alternate-key order effectively demonstrating performance for READ NEXT operations through the primary and alternate keys. Tests were done for 100,000 and 1,000,000 record cases.
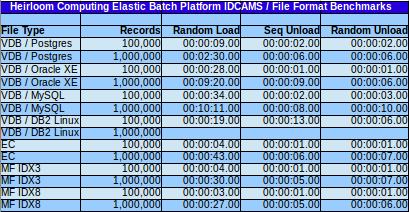
Fig. 1. COBOL file load/unload benchmarks for various file types (protocols).
Results show similar orders of magnitude for all file formats during sequential and random read operations indicating little loss of performance of database-based files over standard files. The times to write COBOL records to a database is higher than that of a file. All databases were connected through JDBC drivers over a network and are otherwise un-tuned from their original installation.
0 Comments