Introduction
Elastic Transaction Platform (ETP), Elastic Batch Platform (EBP) and Elastic COBOL runtime environments are designed for running enterprise applications migrated from a mainframe environment and to scale and be highly-availabile in public or private cloud environments. The system is architected to scale-out across a private or public infrastructure-as-a-service (IaaS). As more power is required additional virtual machines are brought on-line or physical resources (nodes) allocated on the framework and are assigned additional transaction (ETP) or batch (EBP) workload. The scale-out model is in contrast to most other systems in this class (with the notable exception of IBM SYSPLEX) which require scale-up within a frame to increase power. In that model, additional CPUs within the same physical or virtual system are required to increase power. MP Factors limit the scale-up model ... as more CPUs are added synchronization effects among the cores reduces the power of each additional CPU. The scale-out model involving ETP compute nodes and shared-nothing database nodes minimizes the synchronization among nodes to higher level components ... such as page or record level locks rather than words within CPU cache lines.
Further, the pay-as-you-go cloud infrastructure model extends to the Heirloom ETP system. In sync with the op-ex business model, an organization may subscribe to CPU-core-hour power as needed. Only the amount of power actually processing workload is charged-for in this model. With the alternative scale-up model, organizations must "plan for peak" since a physical machine must be configured for a certain number of CPU cores when built and transaction systems are charged on this maximum power available to it.
Architecture
Each compute node in the Heirloom transaction environment is an Heirloom instance built on top of the public/private IaaS. The online transaction processing (OLTP) environment of Heirloom starts with user application programs (transactions) written to the IBM CICS transaction application program interface. The Elastic COBOL compiler translates user COBOL programs into Java code so that they run in common Java Virtual Machine environments. One of these is the Java Enterprise Edition (JEE) Application Server environment. The Elastic Transaction Platform coordinates transactions and implements CICS features and functions such as journals, transient data queues, and distributed program links (DPL) to other ETP regions. ETP runs under control of the JEE server because all user transactions are packaged in Enterprise Archives (.ear files) as Enterprise Java Beans (EJBs). When ETP coordinates DPL communication between the nodes it does so through EJB-to-EJB communication protocols such as EJBD, IIOP and RMI, the same protocols used in other Java enterprise application environments such as IBM Websphere, Oracle Weblogics, Red Hat JBOSS or Apache Geronimo.
User transaction code interacts with CICS file I/O (indexed-sequential file access) API and/or embedded SQL relational database access to store transactional state. For file I/O, ETP maps the application's COBOL record structure to columns and tables in a SQL database. The programs database requests are sent off to the cloud-based SQL database nodes. Figure 1 shows the multi-node Heirloom and database architectures.
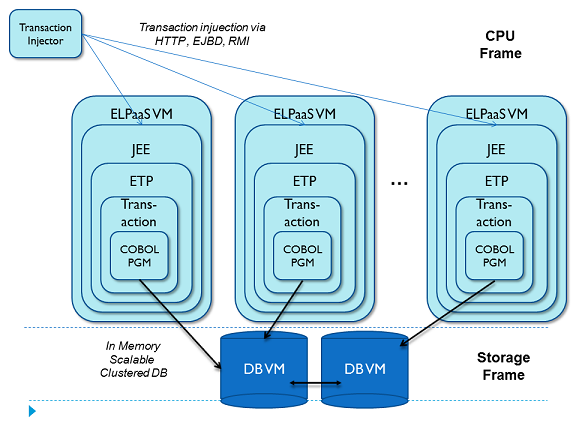
Fig. 1. Structure of transaction COBOL applications in an ETP environment.
In order to compute the cost of the cloud scale-out model relative to the original system, we must find the rough equivalent of an IBM mainframe of a certain known size. The basic process of Performance Benchmarking is to run equivalent workloads at similar speeds on both platforms, the IBM mainframe CICS and the mainframe-migrated ETP environment.
Performance Benchmarks
Initially linked to the clock speed of a processor, the mainframe MIPS (millions of instructions per second) ratings have been expanded to mean the power to execute a certain transaction workload. Machines with differing I/O subsystems, clustering interconnections and memory configurations can generate different MIPS ratings independent of the CPU speed. MIPS ratings of a particular platform may also be affected by software changes to the underlying system since improvements in database searching algorithms, for example, will improve the component score on that benchmark.
IBM provides other performance information in its Large Systems Performance Reference (LSPR). The LSPR changes over time based on how IBM believes their customers are using their systems. Beginning with the introduction of the z990 in 2003, IBM has changed the mix of the benchmarks to include an equal mix of (1) a traditional IMS transaction workload, (2) a workload that includes a traditional CICS/DB2 workload, (3) a WebSphere and DB2 workload, (4) commercial batch with long job steps, and (5) commercial batch with short job steps. Eventually, these configurations are related by third parties back to traditional MIPS ratings. IBM also uses them to generate a metric for Millions of Service Units (MSU), a rating that defines software license costs for various mainframe configurations.
Transaction Processing Benchmarks
Since approximately half of the LSPR can be attributed to transaction benchmarks, it is appropriate to look at transaction processing benchmarks. The transaction processing and database community utilize a series of benchmarks by the Transaction Processing Performance Council (TPC) to measure relative throughput of a system. Since 1993, the TPC-C online transaction processing benchmark has been used to demonstrate the effectiveness of hardware platforms, database systems and transaction systems. One problem with the benchmark has been its popularity – it is now featured in Wall Street Journal advertisements when new records are reached.
TPC-C has become a highly tuned benchmarking vehicle to demonstrate a hardware or software vendor’s effectiveness of their product. And, that is the problem; the benchmark cannot really be used to show the relative strength of one platform against the other because each benchmark run is designed to meet different goals. One of the current performance leaders uses the figures to promote its UNIX database and transaction engine by offloading the business logic to 80 Windows PCs. Another TPC-C performance results show the database vendor stripping the benchmark of its business logic component, choosing to implement the whole of the transaction in procedures embedded in the database itself. The so-called clients merely “kick off” the transactions to execute within the database stored procedures. The TPC-C specification deals with these variations by forcing vendors to compute a total cost of ownership of the entire processing environment. So it means that one person’s TPC-C is a distributed processing benchmark where another’s is a database-only benchmark – the cost is roughly the same.
TPC-C Benchmark
Not enough attention has been paid to keeping the implementation of the TPC-C benchmark static while only varying the hardware and software components. The TPC-C specification as it was written to mimic the data processing needs of a company that must manage, sell or distribute a product or service (e.g., car rental, food distribution, parts supplier, etc.). Although the TPC-C does not attempt to show how to build the application, the guidelines discuss a general-purpose set of order entry and query transactions, occasional “stock” manipulation and reporting functions, with varying inputs (including artificially injected errors) that play havoc on various systems. The TPC-C benchmark was written in such a way that as the simulated company’s business expands, new warehouses and warehouse districts increase as the workload generated by the expanding customers increases. In order to achieve an increase in transaction rate you must add data entry personnel, according to the spec.
The TPC-C specification lays out very simple steps to achieve the end-result of the five transaction types. Each transaction reads a half dozen or more records for various database tables, analyzes them, adds in simulated user input, and updates one or more database records. Each transaction begins from the end-user (data entry personnel) perspective from a menu screen. From there, the benchmark asks to simulate a never-ending session that chooses the 5 transaction types in random fashion with a certain weighting that will carry out a “new order” process about 43% of the time. It is these “new orders” that eventually dictate the transaction benchmark figure, measured qualified throughput (MqTh) specified in transactions per minute (tpmC).
The simple tuning database vendors often perform at this point reorders the list of actions in the specification that define a transaction. It might be to reduce lock contention or the time database records are held with exclusive locks. After this, the hardware or software vendors tune the system to make a point of stressing their component over others that are more or less involved in the benchmark, as a means of meeting the benchmarking criteria.
Heirloom Computing wrote a COBOL implementation of the TPC-C benchmark as a measure of workload but left it essentially untuned from the original specification. The TPC-C spec indicated (although did not mandate) that the application code, transaction control and data control reside on a single system and that network-attached users communicated with the application through a screen interface over a networking protocol. Our transaction benchmark environment maintains this relationship among components because it duplicates application environments that have been used on the mainframe for years and are now subject to migration from the mainframe. The spec defines the user interface as a series of screens. In the COBOL TPC-C the screen interface is handled through the use of CICS BMS maps that lay out the 24-line, 80-column, 3270 terminal screen used for data entry and report generation. The Heirloom technology maps these screens to RESTful Web services --- XML or XHTML transmitted over HTTP protocol.
To complete the benchmarking system, a driver system that injects transactions at a rate and with the proper data defined in the TPC-C spec. The injection system issues HTTP requests and analyzes the return "screen" to generate the request for the follow-up transaction. Each driver simulates hundreds of users issuing transactions to the system. Multiple drivers are started to scale the benchmark workload against the system under test.
Benchmarking Results
The TPC-C benchmark was run under the Heirloom transaction architecture of Fig. 1. The cloud scale-out model allows the number of Heirloom virtual machines (ETP nodes running TPCC) and DB nodes to be added as the work increases. For the benchmark test this was increased from one to two ETP nodes and DB nodes increased from 2 to 4 nodes. The VMWare in-memory database SQLFire was used as a scaleable database for the benchmark. A total of 4 transaction injection nodes were required to pump work into the system. Fig. 2 shows the overall benchmarking system and the results from an hour run.
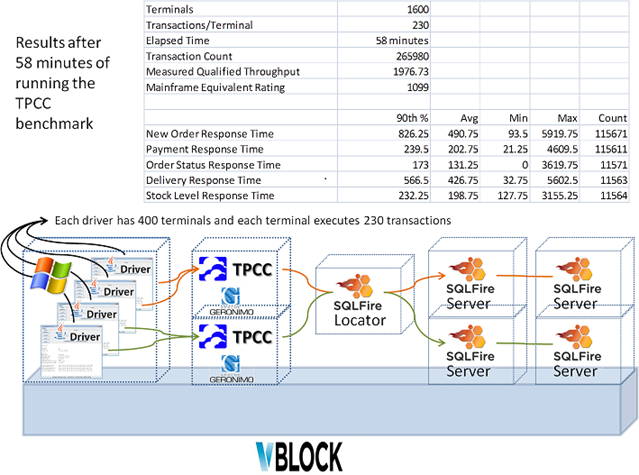
Fig. 2. The benchmarking system and results running in an EMC vBlock hadware environment.
The result of the benchmark run in fig. 2 shows that a mainframe equivalent of 1100 MIPS were processed from two Heirloom nodes running in Linux virtual machines, consisting of 2 CPU cores each. Apache Geronimo 3.0 served as the JEE server hosting ETP and the TPC-C application code structured as CICS regions. The 1100 figure is about double the single-node case. The architecture will scale up accordingly as either CPU cores are added to the compute nodes or the number of nodes are increased.
Scaleability and Availability
Scaling out performance across multiple nodes requires load balancing component. Such a component may be a commercial load balancer from the likes of VMWare/EMC or embedded in network routers. When under control of the Heirloom Elastic Scheduler Platform (ESP) these nodes can be started and stopped on demand. Figure 3 shows these systems being power-up and down to handle the workload at the time.
Fig. 3. The private cloud deployment Infrastructure-as-a-Service (IaaS) environment
In addition to scaling out to arbitrary performance levels, the multi-node model also supports high availability. Since the user application code in most mainframe systems is written to the pseudo-conversational model there is no transaction state that must be maintained in the ETP or JEE EJBs between requests. Any node in the system may fail (hardware or software) and the load balancing component or injection system will re-route the request to a surviving node. The database nodes are similarly configured as highly available in that SQLFire ensures that database records and locks are replicated across multiple DB nodes.
Summary
The Heirloom Elastic Transaction Platform runs enterprise applications migrated from mainframe environments During one benchmark test the equivalent of 1100 mainframe MIPS was shown in an EMC vBlock system consisting of 2 compute nodes.
0 Comments