Elastic COBOL and the Elastic Transaction Platform (ETP) and Elastic Batch Platform (EBP) offer a wide variety of options when interacting with mainframe applications and their data. Elastic COBOL applications are compiled into Java source code that, when compiled into Java class and jar files, can run off the mainframe, on IBM z/OS or on IBM zLinux. Based on the deployment choices one can optimize the use of mainframe resources. This paper describes the different deployment scenarios.
IBM System z Processors
Mainframe applications and subsystems leverage different kinds of System z processors. General Purpose processors run the majority of applications and subsystems. They are charged at the regular rate when it comes to per-MIPS or per-MSU pricing of leased IBM and 3rd party software and comprises the majority of costs associated with running an enterprise IT datacenter. But, other processor configurations are possible for mainframes. Elastic COBOL applications, when compiled to Java, can run directly on zOS in the Java virtual machine environments IBM provides there -- either as a UNIX environment or a JES/JCL environment that invokes that invironment. Elastic COBOL runtime implements a concept of file "protocols" that connect to various file formats and protocols. meaning that connections are made to UNIX/Windows style files by default (and supported by the UNIX environment) or
The System z Integrated Facility for Linux (IFL) is designed to run zLinux, a variant of Linux. When subsystems such as IBM Websphere for zLinux and Elastic COBOL applications compiled to Java applications are deployed onto zLinux they leverage IFLs which are often included in many System z systems for low or no cost. Java is Java, so it runs the same on IBM Thus, migrating applications to zLinux (whether or not from zOS) can lower an installation's overall compute costs.
The z Integrated Information Processor (zIIP) run IBM DB2 subsystems to process database requirements. Certain workloads running on zOS can be marked as "zIIP eligible" by the zOS dispatcher and are run on these lower cost processors. Leveraging zOS as a "database machine" is done by sending transactions over a network to DB2 subsystems where zIIP processors are available. When Elastic COBOL applications containing EXEC SQL statements they use the Java database connection (JDBC) API and the JDBC drivers provided by database vendors. The IBM DB2 JDBC driver complete the connection between Elastic COBOL applications and DB2 on zOS so whether or not those applications are running on Windows, Linux, zOS or zLinux the transactions will appear to DB2 as coming in "from the outside," making them "zIIP eligible" and running at a lower cost.
The z Application Assist Processor (zAAP) is designed to improve performance and lower costs associated with running Java applications on zOS. Elastic COBOL applications compiled to Java are "100% Java" and thus eligible for dispatching to zAAP processors. Although zAAP processors are often included at low or no cost in System z installations, their use is restricted by the zOS dispatcher. Roughly only 25% to 50% of the Java workloads can be dispatched to zAAPs by this restriction but when dispatched they don't use GP processors.
Mainframe Data
Accessing mainframe data can be done in one of two ways: Converting it to "native" file formats and protocols available where the applications are running or connecting "directly" to the zOS datasets. Both have performance and cost implications. Data migration is the most cost effective if the ultimate goal is application migration to a new environment. See figure 1.
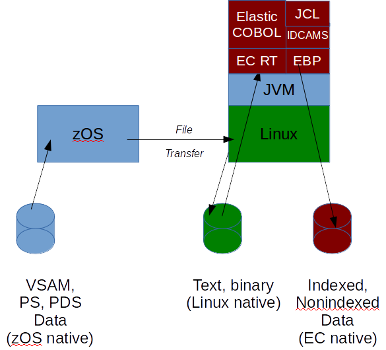
Fig. 1. Data migration from zOS to Linux
Data whether in VSAM KSDS, physical sequential in fixed or variable format with or without block (or other formats) can be "dumped" to binary (EBCDIC) data and transferred to the target platform. Elastic COBOL applications can access directly this EBCDIC data and handle the Record Descriptor Words and Block Descriptor Words that specify record and block boundaries in physical sequential files. EC file protocol "IBM:" is used to deblock and EC runtime "BE" byte encoding indicates that the internal data type is EBCDIC. When programs "display" data to the outside world they are converted from EBCDIC to Unicode, which is the character set encoding used by Java. This is also set with EC compile-time flag to set datatype to IBM ("-dt:ibm"). Default setting is EC ("-dt:ec)" which stores data internally as 8-bit ASCII, the Linux/Windows native format.
Figure 1 also shows a conversion alternative. The Elastic Batch Platform (EBP) IDCAMS utility can restore ("REPRO") files from the EBCDIC format to Indexed (ISAM) or non-indexed file formats that are in EC native protocol. Data conversion from EBCDIC to ASCII is not automatic in these cases as record formats often include COMP-3 (packed decimal), COMP-1 (floating point) or BINARY data in addition to printable EBCDIC. Often applications have copybooks for files that specify the record layout. A COBOL program that loads (from -dt:ibm) and dumps (to -dt:ec) must be used to perform this data conversion following the same copybook layout.
The alternative to migrating the data to a new target environment is to leave the data on the mainframe. There are a number of ways to run applications while leaving the data where it is. The first is the ability to run COBOL applications as Java applications leveraging the Elastic COBOL compiler and its runtime environment. See figure 2.
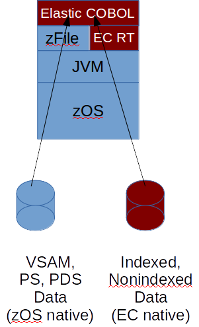
Fig. 2. Elastic COBOL applications accessing mainframe data directly
In this scenario the Elastic COBOL applications use file protocol "vsam:" or "zos:" to reference the VSAM, physical sequential or partitioned dataset. The IBM zFile Java class that is supplied with the IBM Java virtual machine (JVM) environment adapts the native files to the Java environment used by Elastic COBOL. COBOL applications that use standard READ, READ NEXT, READ KEY, REWRITE, DELETE, WRITE statements interact with VSAM or other data directly. The COBOL FILE SECTION and FD specifications provide the connection through the ASSIGN TO clause within the COBOL program (e.g., "ASSIGN TO 'vsam:sys1.vsamfile.dat") to access the primary index or alternate index of a VSAM file. When starting an Elastic COBOL program from within a USS environment on z/OS you would specify the EC DDNAME to dataset through properties:
java -cp ibm-zfile-jar:ecobol.jar:. -Dmydd=zos:sys1.vsamfile.dat myprogram
File specifications lacking the "vsam:" or "zos:" protocol will place their contents in (Elastic COBOL ISAM file format for Indexed files) in non-zOS controlled files stored in Unix files managed by zOS within the Unix subsystem (USS).
Although zFile is implemented by IBM as Java and C/C++ library -- not 100% Java -- IBM has stated that programs that use it are zAAP- or zIIP-eligible. When Elastic COBOL applications are subject to being run on zAAP or zIIP processors at a lower cost than general purpose processors.
An application that has significant CPU requirements as well as I/O requirements can be split using the Elastic COBOL "record and file server". Normally used to access remote files in a distributed environment, the record and file servers can be used on the same system. See figure 3.
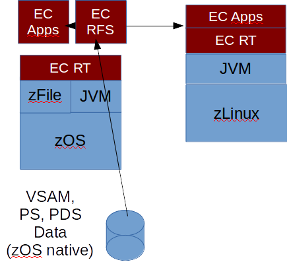
Fig. 3 Elastic COBOL applications connect to the Elastic COBOL Record and File Servers
In this scenario, the record and file servers use the zFile classes to access the native VSAM, PS and PDS data. Record and file servers run as "started tasks" in the zOS environment and can be started through JES/JCL batch jobs or from the USS command line environment or start-up shell scripts. The ASSIGN TO clause has the form "remote:127.0.0.1:zfile:vsam:sys1.vsamfile.dat".
Because zIIP resources may be limited, the Elastic COBOL applications can be moved to other Windows, Linux or as figure 3 shows, zLinux environments. Here the EC Apps again use the record and file servers to access the remote file but use an ASSIGN TO clause that indicates the zOS system, such as "remote:192.168.1.17:zfile:vsam:sys1.vsamfile.dat".
Dataset and protocol specifications need not be given within the Elastic COBOL application. EC supports COBOL data definition names (DDNAMES) such that JVM parameters ("-Dddname=protocol:datasetname") or COBOL command line parameters ("ddname=protocol:datasetname") to the application whether it is run on zOS under JES/JCL or on zLinux environment. Note that EBP can run on zLinux as well meaning that an EBP JCL job can also reference remote files on "// DD" cards contained within it.
The zos: protocol also supports connecting to DD names when run under z/OS BPXBATCH environment from JCL. Use specifications such as -Dddname=zos:DDNAME to link an Elastic COBOL file specification DD name to a z/OS JCL DD card of the same name.
The last scenario (not pictured) allows for Elastic COBOL applications running on Windows or Linux to access native mainframe data through the same record and file servers.
Compile and Runtime Flags
See Elastic COBOL Options for information on compiler and runtime options that affect translation.
Two basic questions must be asked when deciding how to deal with mainframe data in terms of compiler options. Do I want the program to run predominately in "EBCDIC mode" or "ASCII mode?" Then, is my program dealing primarily with "EBCDIC data" or "ASCII data?" Java internally operates in UTF-8 mode, although its possible to change default character sets to be EBCDIC (e.g., code page Cp1047) or ASCII (code-page ISO-8859-1). Compiling a program with "-dt:ibm" sets a number of flags such that EBCDIC data is used and stored internally. Other compiler options (-dt:ec, the default, -dt:mf, -dt:hp, -dt:acu) operate in ASCII (code page ISO-8859-1) mode. By default, EBCDIC mode will write and read EBCDIC data exactly as is represented in COBOL linear memory. However, if a COBOL variable element is "DISPLAYed" that data along with strings on the display statement are generated in the default character set of the JVM. The Java runtime property file.encoding will set file Java file I/O. For example, -Dfile.encoding=Cp1047 will output all data, even to System.out or System.err to EBCDIC ... likely rendering it unreadable when the program is run on a Windows or Linux terminal, or even in JZOS and OMVS operating environments on the mainframe, since these subsystems expect default UTF-8 is in use for Java.
For these reasons, typical use of Elastic COBOL in production operations use -dt:ec (or -dt:mf) when running Java on Windows/Linux servers and -dt:ibm when running on z/OS. This automatically sets the -DBE (COBOL linear address space byte encoding scheme) to the appropriate code page, Cp1047 or ISO-8859-1. Although it is possible to compile programs with one default data type, but set the runtime byte encoding of the memory to be different, it is not recommended. -DBE would more likely be used to "fine tune" the EBCDIC representation, such as with Cp0437, Cp037, or ASCII representation, such as ISO-8859-8, US-ASCII.
Mixed mode operation, where some files are brought down from the mainframe in EBCDIC mode to the distributed platform that deals primarily with ASCII files. Or, z/OS JZOS environment where local files on the JZOS file system are ASCII or UTF-8 used as well as Elastic COBOL's feature of directly addressing Physical Sequential, PDS or VSAM files via the IBM ZFile() native dataset mechanism. When using mixed mode it will likely be necessary to specify encoding on a per-file basis by specifying the -Dddname.encoding property.
When different files within the same program are encoded with different code sets (e.g., ASCII and EBCDIC), the -Dddname.encoding runtime property setting will specify the encoding of a particular file associated with the DDname (ASSIGN TO name) when it is different from default conversion options (file.encoding, ibm.encoding). This options is most useful when running programs in "EBCDIC mode" (-dt:ibm compiler option) where some input files are in ASCII or UTF-8. Or, when operating programs in "ASCII mode" (-dt:ec or -dt:mf compiler options) with some files brought down from the mainframe (EBCDIC data). Note that Java Charset encoding / decoding is performed on entire records such that a record containing "a" (EBCDIC 0x81) is translated to "a" (ISO-8859-1 0x61) allowing a program to compare the PIC X(1) element to the literal constant 'a'. However, an EBCDIC half-word binary number 64 (EBCDIC null+space, 0x0040) would also be translated (ASCII null+space 0x0020) ... and not conform with the expected little-endian binary representation of the number 64 (0x4000) representing a PIC S9(4) BINARY element with default compiler settings.
Note: When connecting to native z/OS files using IBM ZFile class (accessible with the Elastic COBOL file protocol "zos:" prefixing MVS dataset names) no translation is performed. Therefore whether running on a distributed platform (requiring the additional "remote:" file protocol prefix to access remote z/OS datasets) or running under JZOS the data read into COBOL group variables will be EBCDIC.
Note: When using mixed-mode operations choose two code pages that are both reflexive and single-byte in nature, Reflexive means that any character when encoded in a different character set can be decoded back to its original form without change. This is true for Cp1047 and ISO-8859-1. Further, the code pages should represent their characters as single byte because the COBOL linear address space, onto which COBOL variables are mapped, is a single byte. Specifically, this means UTF-8 (UTF-16) should not be used as the default character set. Whereas the letter "a" can be represented as one byte in UTF-8 (0x61), binary data byte with value "254" requires a Unicode escape sequence to represent it in two bytes (0xfffe). After translation a movement of the result into the COBOL linear address space would lose one of those bytes or misalign the linear memory mapping backing the COBOL variables. Elastic COBOL supports the National character set notation and double-byte character set notions which COBOL standards define to store all characters as 2 bytes in its linear address space.

1 Comments