General description
When a mainframe application performs a sequential read on a VSAM file, records are retrieved in an order determined by the EBCDIC collating sequence. By contrast, after the mainframe application has been transformed by Heirloom, the same records are retrieved in an order determined by the ASCII collating sequence. Therefore we implemented the option of using EBCDIC data key column for the retrieval of VSAM/VDB records. The feature is tested to be working with MS SQL Server, DB2 and PostgreSQL.
If flag sql.file.useEbcdicBinaryColumn=true is passed (flag can be passed via command line as described in Transform feature article), the VDB table is loaded with data extracted from the mainframe. An EBCDIC binary index column would be populated with key values in EBCDIC encoding. This approach is used in oppose to varchar column with EBCDIC collation, because of the support for other database other than MS SQL Server.
The new varbinary column is named the same way as the original key column with 'CI_' prefix as can be seen on the screenshot. The new varbinary column is used as primary key and would have a clustered index created. Ebcdic column is created also for every alternate key 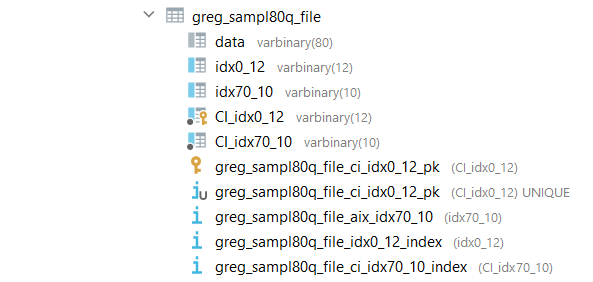
When VDB file is opened, records would be retrieved according to the order of the EBCDIC index column if the EBCDIC index column exists.
For IDCAMS FROMKEY/TOKEY read, we need to specify additional sql.file.useEbcdicBinaryColumn=true configuration in IDCAMS.properties. Thus TOKEY value would be converted to its EBCDIC equivalent before records are compared.
Mixed composite key support
In order to allow for a mix of text and non-text sub-fields in a composite key, we enhances the naming convention of the EBCDIC index column by adding a prefix '_n<i>' right after the 'CI_' prefix where <i> is the index of every non-text sub-key.
For example if we have an ASCII index column idx66_10__76_4 with respective EBCDIC index column ci_idx66_10__76_4, if the second sub-key with offset 76 and length 4 contains non text data, we will be marking it with ci_n1_idx66_10__76_4 where 1 is the index of the key.
If we have two non text fields the column will be named ci_n01_idx66_10__76_4 where 0 and 1 are indexes of the non text sub-fields.
It would be necessary to include new settings in the profile file to enable the Transform utility to distinguish between text and non-text key fields. The example below shows how new settings, provisionally called OUTFILE-PRIMARY-TYPES and OUTFILE-ALTKEY-TYPES, would look when inserted into the profile file.
OUTFILE-PRIMARY-TYPES=[t, t, ...<list of primary key types of every sub-field of the key: n - for non text field, t - for text field>]
OTUFILE-ALTKEY-TYPES=[n, t, ...<list of alt key types of every sub-field of the key: n - for non text field, t - for text field>]
For the example we have primary key idx0_4__4_8 with text sub-keys and alternate key idx66_10__76_4 with one text and one non text sub-keys.
OUTFILE-FORMAT=F
OUTFILE-PRIMARY-OFFSETS=[0, 4]
OUTFILE-PRIMARY-LENGTHS=[4, 8]
OUTFILE-PRIMARY-TYPES=[t, t]
OUTFILE-ALTKEY-OFFSETS=[66, 76]
OUTFILE-ALTKEY-LENGTHS=[10, 4]
OUTFILE-ALTKEY-TYPES=[t, n]
OUTFILE-ALTKEY-DUPS=[true, true]
OUTFILE-ALTKEY-GROUPS=[0, 0]
Alternative solution
Please note that another option is the usage of sql.file.useMSSQLcollateEbcdic for which would not require reuploading of data using Transform. In this solution we perform a case on each select and that leads to major performance problems on larga datasets.
Codepage support
Currently, there is support for two MSSQL EBCDIC codepages:
- SQL_EBCDIC037_CP1_CS_AS and SQL_EBCDIC277_CP1_CS_AS
In order to specify which one you want to use, check the option sql.file.ebcdicCodepage.
sql.file.ebcdicCodepage=(037 or 277)
Note: If sql.file.useMSSQLcollateEbcdic is set to true and no codepage is specified, the default one - SQL_EBCDIC037_CP1_CS_AS is going to be used.
0 Comments